The Tech Behind TikTok's Addictive Recommendation System
Intro
I’ve been using TikTok a lot lately and was curious about the tech behind TikTok’s addictive algorithm, the “Recommendation System.” I visited their official blog post but found limited details on how it works. So, I googled and found two papers “Monolith” and “IPS,” released by ByteDance, TikTok’s parent company, and here is the process as explained by them.
Recommendation features
There are features that influence the recommendation system, which are:
User Features:
- User interactions, such as the videos you like, share, comment on, watch in full or skip, accounts you follow, accounts that follow you, and when you create content.
- User information, such as your device and account settings, language preference, country, time zone and day, and device type.
Content Features:
- Video information, such as captions, sounds, hashtags, number of video views, and the country in which the video was published.
These elements are merged to create detailed user profiles and content embeddings. These profiles and embeddings are then used to tailor content suggestions using a mix of collaborative and content-based approaches.
Model architecture
Embeddings are input to a Deep Factorization Machine, which leverages a deep neural network to capture non-linear and complex patterns from the embeddings, and Factorization Machines to capture linear correlations between different features, which is essential in understanding simple yet effective user-item interactions.
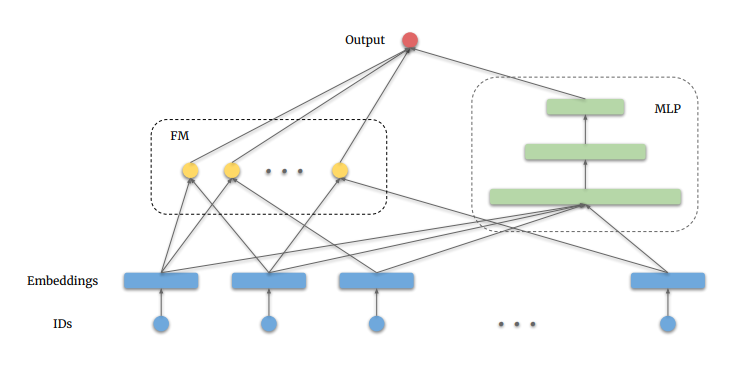 Model Architecture
Model Architecture
Real-Time Online Training
TikTok has to update its recommendation system as fast as possible to account for the non-stationary nature of user data, known as “Concept Drift.” So, there has to be a mechanism that updates the model parameters in real-time.
“Monolith” framework uses a streaming engine that can be used in both batch and online training in a unified design. They use a Kafka queue to log actions of users (clicks, likes, comments, etc.) and another Kafka queue for features. And Flink as a streaming engine/job for joining them to create training examples.
During online training, sparse parameters are updated on a minute-level interval from the training PS (Parameter Synchronization) to the serving PS, which avoids heavy network transmissions or memory spikes.
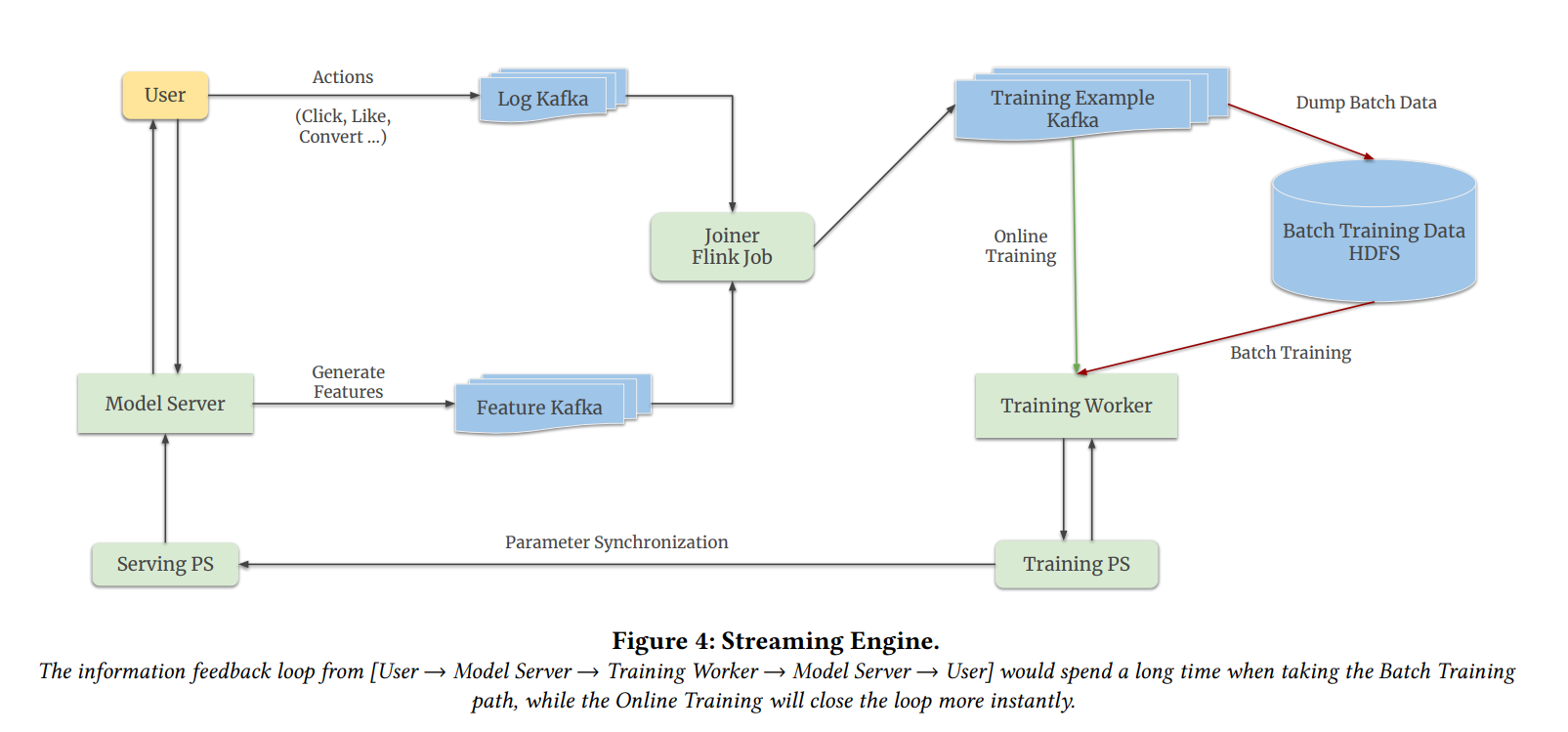 Training Pipeline
Training Pipeline
Monolith uses TensorFlow’s distributed Worker-ParameterServer, where multiple machines work together to train a model. Workers are responsible for performing computations (gradients/parameter updates), while parameter servers are used for storing the current model state like weights and biases.

Managing Large and Dynamic User Data: Embedding Collisions
User data’s vast and dynamic nature poses a challenge, as it can lead to unwieldy embedding sizes and collisions (where different data points are mistakenly identified as identical).
To tackle this, “Monolith” employs “cuckoo hashing.” This method uses two hash tables with separate hash functions, allowing dynamic placement and repositioning of elements to avoid collisions.
Additionally, to prevent the embedding memory from expanding too rapidly, a probabilistic filter and an adjustable expiration period for embeddings are used, effectively managing the memory requirements.
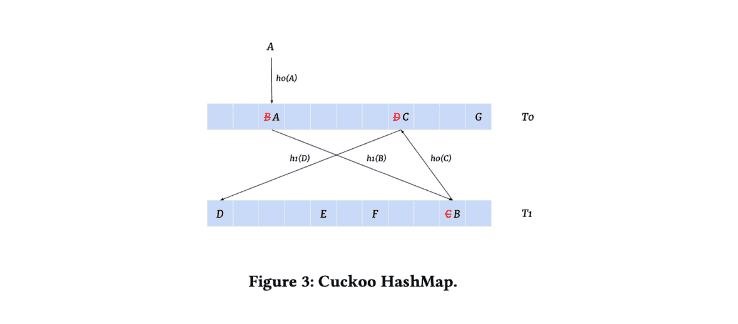
Conclusion
TikTok’s recommendation system played a main role in its success and widespread use. I tried in this blog post to shed some light on the underlying technologies used, especially the online training, which helps them recommend real-time personalized content that keeps users staring at their phones for hours.
References: